Flink CDC 简介
网上有很多介绍,就不搬运了,看这篇就够了
前述
有一个后台系统,需要复杂的查询, 跨越了两个服务(相关表落在两个不同的库里),查询条件,也分别作用于两个系统的关联表;通常做法是,在系统A中先按部分条件查询数据id集合; 出个接口给到另一个系统B, 然后再在系统B中按条件查询数据加一个where条件 relation_id in 系统A给出的id结果集; 如果数据量少,还可以用用,数据量多了,要么性能跟不上,要么直接超过最大sql长度限制了, 这个时候如果能方便的实时的把系统A的数据同步一份到系统B中,做个联表查询问题就解决了;虽然杀鸡用了牛刀,但是我们可以以此为契机, 了解下 Flink CDC
Flink 搭建
参考官方教程
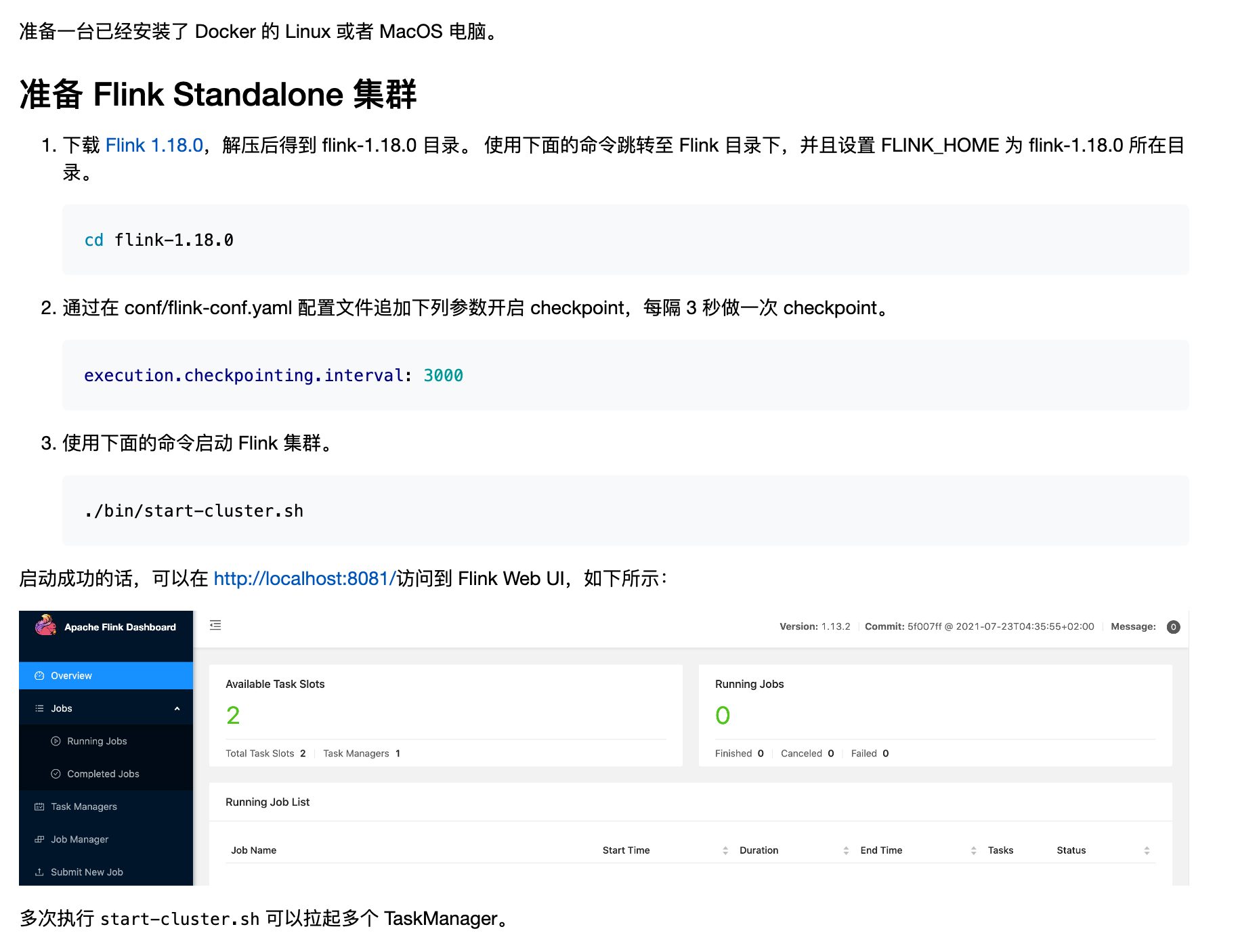
我下载是 flink-1.19.0
官方下载地址:https://flink.apache.org/downloads/
安装过程非常简单 毫无波折
mysql 准备
准备好mysql 资源, 并开启binglog
如果没有现成的合适的资源,需要自己现搭的,点这里
创建一个新的库– mytest,作为源数据库, 并在该库下创建一个表– logtest1
CREATE TABLE `logtest1` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`uid` int(11) unsigned NOT NULL,
`operate_type` int(10) unsigned NOT NULL,
`opeate_detail` varchar(200) NOT NULL,
`create_time` datetime NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4;
创建另一个新的库– test,作为目标数据库, 并在该库下创建一个表– logtest
CREATE TABLE `logtest` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`uid` int(11) unsigned NOT NULL,
`operate_type` int(10) unsigned NOT NULL,
`opeate_detail` varchar(200) NOT NULL,
`create_time` datetime NOT NULL,
`update_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4;
注意我这里多加了一个字段 update_time;
通过 FlinkCDC SQL 提交任务
在这里 下载
flink-sql-connector-mysql-cdc-3.0.0.jar
flink-cdc-pipeline-connector-mysql-3.0.0.jar
并放入 flink-1.19.0 的安装目录下的lib 下, 并执行
./bin/sql-client.sh
这时候你应该会看到一个美丽的小松鼠

依次输入FlinkSql :
CREATE TABLE `logtest1`(
`id` INT NOT NULL,
`uid` INT NOT NULL,
`operate_type` INT NOT NULL,
`opeate_detail` STRING NOT NULL,
`create_time` TIMESTAMP NOT NULL,
PRIMARY KEY (`id`) NOT ENFORCED
)WITH(
'connector' = 'mysql-cdc',
'hostname' = '127.0.0.1',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'mytest',
'table-name' = 'logtest1'
);
CREATE TABLE `logtest`(
`id` INT NOT NULL,
`uid` INT NOT NULL,
`operate_type` INT NOT NULL,
`opeate_detail` STRING NOT NULL,
`create_time` TIMESTAMP NOT NULL,
PRIMARY KEY (`id`) NOT ENFORCED
)WITH(
'connector' = 'jdbc',
'url' = 'jdbc:mysql://127.0.0.1:3306/test?characterEncoding=utf8&useSSL=true&serverTimezone=Asia/Shanghai',
'driver' = 'com.mysql.cj.jdbc.Driver',
'username' = 'root',
'password' = '123456',
'table-name' = 'logtest'
);
insert into logtest select * from logtest1;
这时在 mytest.logtest1 插入一条数据
INSERT INTO
logtest1(id,uid,operate_type,opeate_detail,create_time) VALUES (1, 1111, 1, ‘ssssdddd66661111’, ‘2024-03-28 10:58:00’);
预期 数据 应该能出现在 test.logtest 中
但是不出意外的是,意外发生了, 实际 test.logtest 依旧空空
经查报错信息如下:
org.apache.flink.table.api.ValidationException: Could not find any factory for identifier 'jdbc' that implements 'org.apache.flink.table.factories.DynamicTableFactory' in the classpath.
Available factory identifiers are:
blackhole
datagen
filesystem
kafka
print
upsert-kafka
在Flink运行时上下文中可能:
缺少flink与jdbc的连接适配器
缺少 mysql 的 jdbc 驱动包
检查${FLINK_HOME}/lib下是否包含如下名称的jar (仅举例,忽略版本号):
flink-connector-jdbc-3.1.2-1.18.jar
mysql-connector-java-8.0.27.jar
下载地址:
https://repo1.maven.org/maven2/mysql/mysql-connector-java/
https://repo1.maven.org/maven2/org/apache/flink/
最终lib下的文件如下

重启服务后,输入FlinkSql 再来一遍,
./bin/stop-cluster.sh
./bin/start-cluster.sh
./bin/sql-client.sh
在 mytest.logtest1 插入数据或者更新数据,在test.logtest中观察,数据精准同步
至此,算简单入门了,后面的路还有很远很远
使用技巧
多表汇总
有时候我们使用了分表,但是后台查询的时候希望查询到所有符合条件的数据,以本案为例:
我们再创建一个表 mytest.logtest2,结构与 mytest.logtest1相同; 期望把 mytest.logtest1, mytest.logtest2的数据都同步到 test.logtest 中
那么我们只需要改下这里就行了
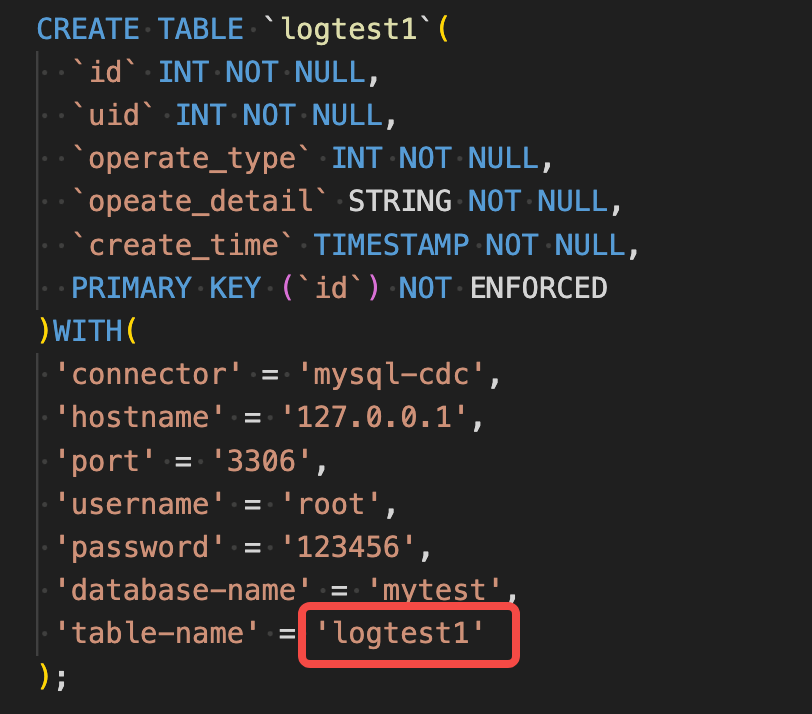
把这里设置为 ‘table-name’ = ‘logtest[1-9]’ 就可以实现logtest1, logtest2… 等多表的数据同步, 表名支持正则表达式
选择性处理新增、更新、删除数据
在flinkCDC源数据配置,可以通过debezium.skipped.operations参数控制,配置需要过滤的 oplog 操作。操作包括 c 表示插入,u 表示更新,d 表示删除。默认情况下,不跳过任何操作,以逗号分隔。配置多个操作,需要英文逗号分隔。
官方说明:Debezium connector for MySQL :: Debezium Documentation

参数说明
记录下有空详细研究
MySQL CDC 源表参数
| 参数 | 是否必填 | 默认值 | 数据类型 | 描述 |
|---|---|---|---|---|
| connector | 是 | 无 | String | 连接器,固定值为 mysql-cdc。 |
| hostname | 是 | 无 | String | MySQL 数据库 IP 地址。 |
| username | 是 | 无 | String | MySQL 数据库用户名。 |
| password | 是 | 无 | String | MySQL 数据库密码。 |
| database-name | 是 | 无 | String | MySQL 数据库名称,支持正则匹配多个数据库。 |
| table-name | 是 | 无 | String | MySQL 表名,支持正则匹配多张表名。 |
| port | 否 | 3306 | String | MySQL 数据库端口号。 |
| server-id | 否 | 无 | String | 数据库客户端的一个数字ID,该ID必须是MySQL集群中全局唯一的,建议针对同一个数据库的每个作业都设置一个不同的 ID。默认会随机生成一个 5400~6400 的值。该参数也支持 ID 范围的格式,例如 5400-5408。 |
| server-time-zone | 否 | UTC | String | 会话时区,例如:”Asia/Shanghai”。控制 MYSQL 中的 TIMESTAMP 类型如何转换为 STRING。详细请参考官方文档。 |
| debezium.min.row.count.to.stream.results | 否 | 1000 | Integer | 首次读取数据时,当表的条数大于该值,则使用分批读取模式。设置为 ‘0’ 跳过检查始终用流式传输读取数据。 |
| debezium.* | 否 | 无 | String | 传递 Debezium 的属性,如:’debezium.snapshot.mode’ = ‘never’。更多信息请查看 Debezium 的 MySQL 连接器属性。 |
类型映射
| MySQL 字段类型 | Flink SQL 字段类型 |
|---|---|
| TINYINT | TINYINT |
| SMALLINT TINYINT UNSIGNED | SMALLINT |
| INT MEDIUMINT SMALLINT UNSIGNED | INT |
| BIGINT INT UNSIGNED | BIGINT |
| BIGINT UNSIGNED | DECIMAL(20, 0) |
| BIGINT | BIGINT |
| FLOAT | FLOAT |
| DOUBLE DOUBLE PRECISION | DOUBLE |
| NUMERIC(p, s) DECIMAL(p, s) | DECIMAL(p, s) |
| BOOLEAN TINYINT(1) | BOOLEAN |
| DATE | DATE |
| TIME [(p)] | TIME [(p)] [WITHOUT TIMEZONE] |
| DATETIME [(p)] | TIMESTAMP [(p)] [WITHOUT TIMEZONE] |
| CHAR(n) VARCHAR(n) TEXT | STRING |
| BINARY VARBINARY BLOB | BYTES |
源表with下的属性
chunk-key.even-distribution.factor.lower-bound:块键(Chunk Key)的均匀分布因子下限。
chunk-key.even-distribution.factor.upper-bound:块键的均匀分布因子上限。
chunk-meta.group.size:块元数据的分组大小。
connect.max-retries:连接重试的最大次数。
connect.timeout:连接的超时时间。
connection.pool.size:连接池的大小。
connector:使用的连接器的名称。
database-name:数据库的名称。
heartbeat.interval:心跳间隔时间。
hostname:主机名或 IP 地址。
password:连接到数据库或其他系统所需的密码。
port:连接的端口号。
property-version:属性版本。
scan.incremental.snapshot.chunk.key-column:增量快照的块键列。
scan.incremental.snapshot.chunk.size:增量快照的块大小。
scan.incremental.snapshot.enabled:是否启用增量快照。
scan.newly-added-table.enabled:是否启用新加入表的扫描。
scan.snapshot.fetch.size:从状态快照中获取的每次批量记录数。
scan.startup.mode:扫描启动模式。
scan.startup.specific-offset.file:指定启动位置的文件名。
scan.startup.specific-offset.gtid-set:指定启动位置的 GTID 集合。
scan.startup.specific-offset.pos:指定启动位置的二进制日志位置。
scan.startup.specific-offset.skip-events:跳过的事件数量。
scan.startup.specific-offset.skip-rows:跳过的行数。
scan.startup.timestamp-millis:指定启动时间戳(毫秒)。
server-id:服务器 ID。
server-time-zone:服务器时区。
split-key.even-distribution.factor.lower-bound:切分键(Split Key)的均匀分布因子下限。
split-key.even-distribution.factor.upper-bound:切分键的均匀分布因子上限。
table-name:表名。
username:连接到数据库或其他系统所需的用户名。
Sink目标表with下的属性:
connection.max-retry-timeout:连接重试的最大超时时间。
connector:使用的连接器的名称。
driver:JDBC 连接器中使用的数据库驱动程序的类名。
lookup.cache:查找表的缓存配置。
lookup.cache.caching-missing-key:是否缓存查找表中的缺失键。
lookup.cache.max-rows:查找表缓存中允许的最大行数。
lookup.cache.ttl:查找表缓存中行的生存时间。
lookup.max-retries:查找操作的最大重试次数。
lookup.partial-cache.cache-missing-key:是否缓存查找表部分缺失的键。
lookup.partial-cache.expire-after-access:查找表部分缓存中行的访问到期时间。
lookup.partial-cache.expire-after-write:查找表部分缓存中行的写入到期时间。
lookup.partial-cache.max-rows:查找表部分缓存中允许的最大行数。
password:连接到数据库或其他系统所需的密码。
property-version:属性版本。
scan.auto-commit:是否自动提交扫描操作。
scan.fetch-size:每次批量获取记录的大小。
scan.partition.column:用于分区的列名。
scan.partition.lower-bound:分区的下限值。
scan.partition.num:要扫描的分区数量。
scan.partition.upper-bound:分区的上限值。
sink.buffer-flush.interval:将缓冲区的数据刷新到目标系统的时间间隔。
sink.buffer-flush.max-rows:缓冲区中的最大行数,达到此值时将刷新数据。
sink.max-retries:写入操作的最大重试次数。
sink.parallelism:写入任务的并行度。
table-name:表名。
url:连接到数据库或其他系统的 URL。
username:连接到数据库或其他系统所需的用户名。
学习资料
https://blog.csdn.net/weixin_43563705/article/details/107604693
https://flink.apache.org/zh/what-is-flink/flink-operations/
https://nightlies.apache.org/flink/flink-docs-release-1.13/zh/docs/try-flink/flink-operations-playground/